(最近没有做多少Linux system level的事情了,看着草稿箱中还有以前写的这篇文章,凑合着发出来吧)
从http://www.coker.com.au/bonnie++/ 网页下载bonnie++-1.03e.tgz 文件,然后解压,对其进行配置、编译、安装的命令行操作如下:
[root@kvm-guest ~]# cd bonnie++-1.03e
[root@kvm-guest bonnie++-1.03e]# ./configure
[root@kvm-guest bonnie++-1.03e]# make
[root@kvm-guest bonnie++-1.03e]# make install
本次测试使用Bonnie++的命令如下:
bonnie++ -D -m kvm-guest -x 3 -u root
其中,-D 表示在批量IO测试时使用直接IO的方式(O_DIRECT),-m kvm-guest 表示Bonnie++得到的主机名为kvm-guest,-x 3 表示循环执行3遍测试,-u root 表示以root用户运行测试。
在执行完测试后,默认会在当前终端上输出测试结果。可以将其CSV格式的测试结果通过Bonnie++提供的bon_csv2html转化为更容易读的HTML文档,命令行操作如下:
[root@kvm-guest bonnie++-1.03e]# echo "native,4G,102817,88,58631,25,56712,4,108330,91,151383,7,299.0,1,16,+++++,+++,+++++,+++,+++++,+++,+++++,+++,+++++,+++,+++++,+++" | perl bon_csv2html > native-bonnie-1.html
Bonnie++是一个强大的测试硬盘和文件系统的工具,关于Bonnie++命令的用法,可以用man bonnie++ 命令获取帮助手册,关于Bonnie++工具的原理及测试方法的简介,可以参考其源代码中的 readme.html 文档。
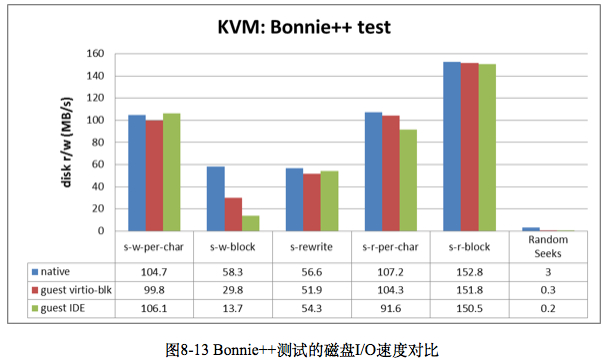
对KVM虚拟化用bonnie++做磁盘I/O的性能测试,结果如下:
Bonnie++的测试结果对比,如图8-13所示,其中的s-w表示顺序写(sequential write)、s-r表示顺序读(sequential read),故s-w-per-char 就表示按字符的顺序写,s-w-block表示按块的顺序写,s-rewrite表示顺序重写,s-r-per-char按字符的顺序读,s-r-block表示按块的顺序读,Random Seeks表示随机改变文件读写指针偏移量(使用lseek()和random()函数)。
http://www.garloff.de/kurt/linux/bonnie/
Bonnie is a simple but useful tool to determine the speed of your filesystem, your OS' caching, the underlying device and your libc.
It does the following benchmarks:
char output with putc() / putc_unlocked()
The result is the performance a program will see that uses putc() to write single characters. On most systems, the speed for this is limited by the overhead of the library calls into the libc, not by the underlying device. The _unlocked version (used if bonnie is called with -u) may be considerably faster, as it involves less overhead.
char input with getc() / getc_unlocked()
The result is the performance a program will see that uses getc() to read single characters. The same comments apply as to putc().
block output with write()
The speed with which your program can output data to the underlying filesystem and device writing blocks to a file with write(). As writes are buffered on most systems, you will see numbers that are much higher than the actual speed of your device, unless you sync() after the writes (option -y) or use a considerably larger size for your testfile than your OS will buffer. For Linux, this is almost all your main memory.
If called with the -o_direct option, this operation (and the ones described in the following two paragraphs) are done with the O_DIRECT flag set, which results in direct DMA from your hardware to userspace, thus avoiding CPU overhead copying buffers around. This will prevent buffering, and gives a much better estimate of real hardware speed also for small test sizes.
block input with read()
The speed with which you can read blocks of data from a file with read(). The same comment as for block output regarding your OS doing buffering for you applies. With the exception that using -y does not help to get realistic numbers for reading. You would need to flush the buffers of the underlying block device, but this turns out to not be trivial as you first have to find out the block device ... It'd a be Linux only feature anyway.
block in/out rewrite
bonnie does a read(), changes a few bytes, write()s the data back and reread()s it. This is pattern that occurs e.g. on some database applications. Its result tells you how your operating / file system can handle such access patterns.
Seeks
Multiple processes do random lseek(). The idea of using multiple processes is to always have outstanding lseek() requests, so the device (disk) stays busy. Seek time is an indication, how good your OS can order seeks and how fast your hardware actually can do random accesses.